49 | 推荐系统(上):如何实现基于相似度的协同过滤?





讲述:黄申
时长08:02大小7.37M
你好,我是黄申。
个性化推荐这种技术在各大互联网站点已经普遍使用了,系统会根据用户的使用习惯,主动提出一些建议,帮助他们发现一些可能感兴趣的电影、书籍或者是商品等等。在这方面,最经典的案例应该是美国的亚马逊电子商务网站,它是全球最大的 B2C 电商网站之一。在公司创立之初,最为出名的就是其丰富的图书品类,以及相应的推荐技术。亚马逊的推荐销售占比可以达到整体销售的 30% 左右。可见,对于公司来说,推荐系统也是销售的绝好机会。因此,接下来的两节,我会使用一个经典的数据集,带你进行推荐系统核心模块的设计和实现。
MovieLens 数据集
在开始之前,我们先来认识一个知名的数据集,MovieLens。你可以在它的主页查看详细的信息。这个数据集最核心的内容是多位用户对不同电影的评分,此外,它也包括了一些电影和用户的属性信息,便于我们研究推荐结果是不是合理。因此,这个数据集经常用来做推荐系统、或者其他机器学习算法的测试集。
时至今日,这个数据集已经延伸出几个不同的版本,有不同的数据规模和更新日期。我这里使用的是一个最新的小规模数据集,包含了 600 位用户对于 9000 部电影的约 10 万条评分,最后更新于 2018 年 9 月。你可以在这里下载:http://files.grouplens.org/datasets/movielens/ml-latest-small.zip。
解压了这个 zip 压缩包之后,你会看到 readme 文件和四个 csv 文件(ratings、movies、links 和 tags)。其中最重要的是 ratings,它包含了 10 万条评分,每条记录有 4 个字段,包括 userId、movieId、rating、timestamp。userId 表示每位用户的 id,movieId 是每部电影的 ID,
rating 是这位用户对这部电影的评分,取值为 0-5 分。timestamp 是时间戳。而 movies 包含了电影的主要属性信息,title 和 genres 分别表示电影的标题和类型,一部电影可以属于多种类型。links 和 tags 则包含了电影的其他属性信息。我们的实验主要使用 ratings 和 movies 里的数据。
设计的整体思路
有了用于实验的数据,接下来就要开始考虑如何设计这个推荐系统。我在第 38 期讲解了什么是协同过滤推荐算法、基于用户的协同过滤和基于物品的协同过滤。这一节我们就以协同过滤为基础,分别实现基于用户和物品的过滤。
根据协同过滤算法的核心思想,整个系统可以分为三个大的步骤。
第一步,用户评分的标准化。因为有些用户的打分比较宽松,而有些用户打分则比较挑剔。所以,我们需要使用标准化或者归一化,让不同用户的打分具有可比性,这里我会使用z 分数标准化。
第二步,衡量和其他用户或者物品之间的相似度。我们这里的物品就是电影。在基于用户的过滤中,我们要找到相似的用户。在基于物品的过滤中,我们要找到相似的电影。我这里列出计算用户之间相似度 和物品之间相似度 的公式。之前我们讲过,这些都可以通过矩阵操作来实现。
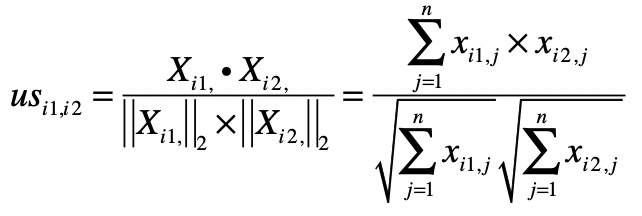

我们以基于用户的过滤为例。假设我们使用夹角余弦来衡量相似度,那么我们就可以采用用户评分的矩阵点乘自身的转置来计算余弦夹角。用户评分的矩阵 中,每一行是某位用户的行向量,每个分量表示这位用户对某部电影的打分。而矩阵 的每一列是某个用户的列向量,每个分量表示用户对某部电影的打分。
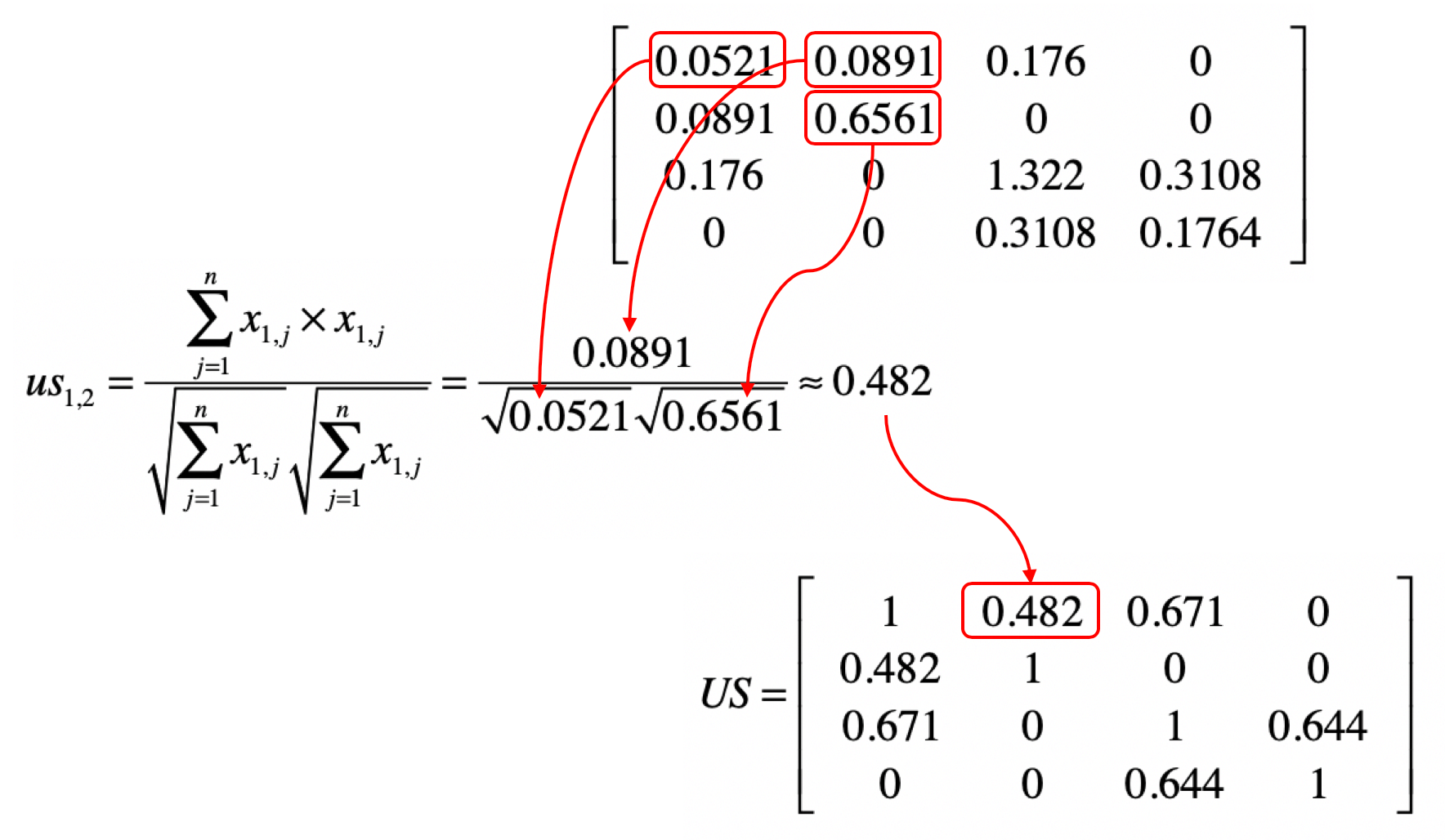
我们假设 的结果为矩阵 ,那么 就表示用户 和用户 这两者喜好度向量的点乘结果,它就是夹角余弦公式中的分子。如果 等于 ,那么这个计算值也是夹角余弦公式分母的一部分。从矩阵的角度来看, 中任何一个元素都可能用于夹角余弦公式的分子,而对角线上的值会用于夹角余弦公式的分母。因此,我们可以利用 来计算任何两个用户之间的相似度。
之前我们使用了一个示例讲解过对于基于用户的协同过滤,如何计算矩阵 ,以及如何使用 来计算余弦夹角,我这里列出来给你参考。

第三步,根据相似的用户或物品,给出预测的得分 p。
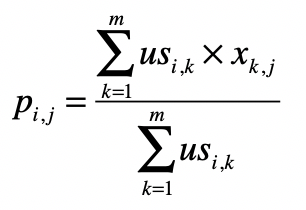
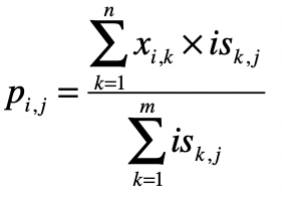
之前我们也解释过如何使用矩阵操作来实现这一步。还是以基于用户的过滤为例。假设通过第二步,我们已经得到用户相似度矩阵 , 和评分矩阵 的点乘结果为矩阵 。沿用前面的示例,结果就是下面这样。

然后对 按行求和,获得矩阵 。

最终,我们使用 和 的元素对应除法,就可以求得任意用户对任意电影的评分矩阵 。

有了这个设计的思路,下面我们就可以使用 Python 进行实践了。
核心 Python 代码
在实现上述设计的三个主要步骤之前,我们还需要把解压后的 csv 文件加载到数组,并转为矩阵。下面我列出了主要的步骤和注释。需要注意的是,由于这个数据集中的用户和电影 ID 都是从 1 开始而不是从 0 开始,所以需要减去 1,才能和 Python 数组中的索引一致。
加载了数据之后,第一步就是对矩阵中的数据,以行为维度,进行标准化。
第二步是计算表示用户之间相似度的矩阵 US。其中,y 变量保存了矩阵 X 左乘转置矩阵 X’的结果。而利用 y 变量中的元素,我们很容易就可以得到不同向量之间的夹角余弦。
在最后一步中,我们就可以进行基于用户的协同过滤推荐了。需要注意的是,我们还需要使用元素对应的除法来实现归一化。
我们可以来看一个展示推荐效果的例子。在原始的评分数据中,我们看到 ID 为 1 的用户并没有对 ID 为 2 的电影进行评分。而在最终的矩阵 P 中,我们可以看系统对用户 1 给电影 2 的评分做出了较高的预测,换句话说,系统认为用户 1 很可能会喜好电影 2。进一步研究电影的标题和类型,我们会发现用户 1 对《玩具总动员》(1995 年)这类冒险类和动作类的题材更感兴趣,所以推荐电影 2《勇敢者的游戏》(1995 年)也是合理的。
总结
在今天的内容中,我通过一个常用的实验数据,设计并实现了最简单的基于用户的协同过滤。我们最关心的是这个数据中,用户对电影的评分。有了这种二元关系,我们就能构建矩阵,并通过矩阵的操作来发现用户或物品之间的相似度,并进行基于用户或者物品的协同过滤。对于最终的计算结果,你可以尝试分析针对不同用户的推荐,看看协同过滤推荐的效果是不是合理。
在你分析推荐结果的时候,可能会参考 movie.csv 这个文件中所描述的电影类型。这些电影类型都是一开始人工标注好的。那么,有没有可能在没有这种标注数据的情况下,在一定程度上自动分析哪些电影属于同一个或者近似的类型呢?如果可以,有没有可能在这种自动划分电影类型的基础之上,给出电影的推荐呢?下一节,我会通过 SVD 奇异值分解,来进行这个方向的尝试。
思考题
今天我使用 Python 代码实现了基于用户的协同过滤。类似地,我们也可以采用矩阵操作来实现基于物品的协同过滤,请使用你擅长的语言来实现试试。
欢迎留言和我分享,也欢迎你在留言区写下今天的学习笔记。你可以点击“请朋友读”,把今天的内容分享给你的好友,和他一起精进。

精选留言(3)
 qinggeouy...2019-04-21 2# 优化了一下,运行时间减少一半以上
qinggeouy...2019-04-21 2# 优化了一下,运行时间减少一半以上
# https://github.com/qinggeouye/GeekTime/blob/master/MathematicProgrammer/49_recommendSystem/lesson49_2.py
import numpy as np
import pandas as pd
from sklearn.preprocessing import scale
import time
"""
对 lesson49_1.py 优化:矩阵操作
"""
# 运行开始时间
time_start = time.time()
# 加载用户对电影对评分数据
df = pd.read_csv("ml-latest-small/ratings.csv")
# 获取用户对数量和电影对数量
user_num = df["userId"].max()
movie_num = df["movieId"].max()
# 构造用户对电影的二元关系矩阵
user_rating = np.zeros((user_num, movie_num))
# 由于用户和电影的 ID 都是从 1 开始,为了和 Python 的索引一致,减去 1
df["userId"] = df["userId"] - 1
df["movieId"] = df["movieId"] - 1
for index in range(user_num):
user_rating[index][df[df["userId"] == index]["movieId"]] = df[df["userId"] == index]["rating"]
# 把二维数组转化为矩阵
x = np.mat(user_rating)
# 对每一行对数据,进行标准化
x_s = scale(x, with_mean=True, with_std=True, axis=1)
# 获取 XX'
y = x_s.dot(x_s.transpose())
# 夹角余弦的分母
v = np.zeros((np.shape(y)[0], np.shape(y)[1]))
v[:] = np.diag(y)
# 获用户相似度矩阵 US , 对应位置上元素相除
us = y/v
# 通过用户之间的相似度,计算 USP 矩阵
usp = np.mat(us).dot(x_s)
# 求用于归一化的分母 按行求和
usr = np.sum(us, axis=1)
# 进行元素对应的除法 归一化
p = np.divide(usp, np.mat(usr).transpose())
# 运行结束时间
time_end = time.time()
print(p)
print(np.shape(p))
print("程序运行耗时:", time_end - time_start)展开作者回复: 感谢代码的优化🙏
 CarreyWan...2019-04-08 1您好,对于上面的代码有三个问题
CarreyWan...2019-04-08 1您好,对于上面的代码有三个问题
第一:
# 设置用户对电影的评分
i += 1
if i % 10000 == 0:
print(i)
这里仅仅是为了打印出i吗??
第二:
计算矩阵时直接运行会有分母为0的情况导致报错。
第三:
最后一行代码是不是写错了??少个括号把。。。
p = divide(usp, mat(usr).transpose()展开作者回复: 第1个只是为了显示加载进度,因为在我的机器上有点慢。
第2个是很好的点,可以让分母加一个很小的值避免分母为0
第3个确实漏了一个括号,回头补上
感谢看得这么仔细,帮我找出了2个笔误 🤝 冄~2019-04-28老师好,感觉按照公式来看,USR作为分母,第一行应该是US的第一行元素求和(1+0.482+0.671+0=2.153),而不是USP的第一行求和(0.500+0.790+0.496=1.786)。否则会像文中一样,p矩阵每行求和为1也是因为USR这样计算导致的。代码部分usr[userId] = sum(us[userId])应该是对的。不知我理解得对不对?展开
冄~2019-04-28老师好,感觉按照公式来看,USR作为分母,第一行应该是US的第一行元素求和(1+0.482+0.671+0=2.153),而不是USP的第一行求和(0.500+0.790+0.496=1.786)。否则会像文中一样,p矩阵每行求和为1也是因为USR这样计算导致的。代码部分usr[userId] = sum(us[userId])应该是对的。不知我理解得对不对?展开作者回复: 我回头仔细看一下,可能是个笔误


