极客时间-徐文浩-《深入浅出计算机组成原理》
零散笔记,不成体系。
浮点数和定点数
GPU/TPU/FPGA
CPU
CPU、缓存和内存的关系:
- cache line (64KB)
- cache和内存地址映射
- 缓存读取
- 缓存写入
- 缓存一致性:比分布式系统的数据一致性简单,因为不用考虑网络传输延迟和异常。
- 写传播
- 事务串行化
- 总线嗅探
- MESI协议
参考 * 与程序员相关的CPU缓存知识。 * Github上的一个代码库 hardware-effects 里面有受CPU影响的程序的演示。 > This repository demonstrates various hardware effects that can degrade application performance in surprising ways and that may be very hard to explain without knowledge of the low-level CPU and OS architecture.
内存
- 虚拟内存地址
- 物理内存地址
- 页表
- 简单页表
- 多级页表:时间换空间,树形结构
- 加速地址转换(TLB):通过在CPU中放置cache可以快速进行虚拟内存地址到物理内存地址的转换。
- 内存保护
- 可执行空间保护
- 地址空间布局随机化
CPU架构
CISC和RISC
- 复杂指令集(Complex Instruction Set Computing,简称 CISC)
- 精简指令集(Reduced Instruction Set Computing,简称 RISC)
当时,UC Berkeley的大卫·帕特森(David Patterson)教授发现,实际在CPU运行的程序里,80%的时间都是在使用20%的简单指令。于是,他就提出了RISC的理念。自此之后,RISC类型的CPU开始快速蓬勃发展。
在RISC架构里面,CPU选择把指令“精简”到20%的简单指令。而原先的复杂指令,则通过用简单指令组合起来来实现,让软件来实现硬件的功能。这样,CPU的整个硬件设计就会变得更简单了,在硬件层面提升性能也会变得更容易了。
RISC的CPU里完成指令的电路变得简单了,于是也就腾出了更多的空间。这个空间,常常被拿来放通用寄存器。因为RISC完成同样的功能,执行的指令数量要比CISC多,所以,如果需要反复从内存里面读取指令或者数据到寄存器里来,那么很多时间就会花在访问内存上。于是,RISC架构的CPU往往就有更多的通用寄存器。
ARM和RISC-V:CPU的现在与未来
2017年,ARM公司的CEO Simon Segards宣布,ARM累积销售的芯片数量超过了1000亿。作为一个从12个人起步,在80年代想要获取Intel的80286架构授权来制造CPU的公司,ARM是如何在移动端把自己的芯片塑造成了最终的霸主呢?
ARM这个名字现在的含义,是“Advanced RISC Machines”。你从名字就能够看出来,ARM的芯片是基于RISC架构的。不过,ARM能够在移动端战胜Intel,并不是因为RISC架构。
到了21世纪的今天,CISC和RISC架构的分界已经没有那么明显了。Intel和AMD的CPU也都是采用译码成RISC风格的微指令来运行。而ARM的芯片,一条指令同样需要多个时钟周期,有乱序执行和多发射。我甚至看到过这样的评价,“ARM和RISC的关系,只有在名字上”。
ARM真正能够战胜Intel,我觉得主要是因为下面这两点原因。
第一点是功耗优先的设计。一个4核的Intel i7的CPU,设计的时候功率就是130W。而一块ARM A8的单个核心的CPU,设计功率只有2W。两者之间差出了100倍。在移动设备上,功耗是一个远比性能更重要的指标,毕竟我们不能随时在身上带个发电机。ARM的CPU,主频更低,晶体管更少,高速缓存更小,乱序执行的能力更弱。所有这些,都是为了功耗所做的妥协。
第二点则是低价。ARM并没有自己垄断CPU的生产和制造,只是进行CPU设计,然后把对应的知识产权授权出去,让其他的厂商来生产ARM架构的CPU。它甚至还允许这些厂商可以基于ARM的架构和指令集,设计属于自己的CPU。像苹果、三星、华为,它们都是拿到了基于ARM体系架构设计和制造CPU的授权。ARM自己只是收取对应的专利授权费用。多个厂商之间的竞争,使得ARM的芯片在市场上价格很便宜。所以,尽管ARM的芯片的出货量远大于Intel,但是收入和利润却比不上Intel。
不过,ARM并不是开源的。所以,在ARM架构逐渐垄断移动端芯片市场的时候,“开源硬件”也慢慢发展起来了。一方面,MIPS在2019年宣布开源;另一方面,从UC Berkeley发起的RISC-V项目也越来越受到大家的关注。而RISC概念的发明人,图灵奖的得主大卫·帕特森教授从伯克利退休之后,成了RISC-V国际开源实验室的负责人,开始推动RISC-V这个“CPU届的Linux”的开发。可以想见,未来的开源CPU,也多半会像Linux一样,逐渐成为一个业界的主流选择。如果想要“打造一个属于自己CPU”,不可不关注这个项目。
FPGA和ASIC
FPGA,也就是现场可编程门阵列(Field-Programmable Gate Array)。看到这个名字,你可能要说了,这里面每个单词单独我都认识,放到一起就不知道是什么意思了。
没关系,我们就从FPGA里面的每一个字符,一个一个来看看它到底是什么意思。
- P代表Programmable,这个很容易理解。也就是说这是一个可以通过编程来控制的硬件。
- G代表Gate也很容易理解,它就代表芯片里面的门电路。我们能够去进行编程组合的就是这样一个一个门电路。
- A代表的Array,叫作阵列,说的是在一块FPGA上,密密麻麻列了大量Gate这样的门电路。
- 最后一个F,不太容易理解。它其实是说,一块FPGA这样的板子,可以进行在“现场”多次地进行编程。它不像PAL(Programmable Array Logic,可编程阵列逻辑)这样更古老的硬件设备,只能“编程”一次,把预先写好的程序一次性烧录到硬件里面,之后就不能再修改了。
ASIC(Application-Specific Integrated Circuit),也就是专用集成电路。比如,现在手机里就有专门用在摄像头里的芯片;录音笔里会有专门处理音频的芯片,都是ASIC。
那么,我们能不能用刚才说的FPGA来做ASIC的事情呢?当然是可以的。我们对FPGA进行“编程”,其实就是把FPGA的电路变成了一个ASIC。这样的芯片,往往在成本和功耗上优于需要做通用计算的CPU和GPU。但是,FPGA一样有缺点,那就是它的硬件上有点儿“浪费”。为了实现通用性,FPGA有很多荣誉的硬件。
HDD和SSD
硬盘接口:
- SATA3.0:带宽6Gb/s,理论传输上线768MB/s。
- PCI Express接口
PCI Express接口上的SSD硬盘性能测试:
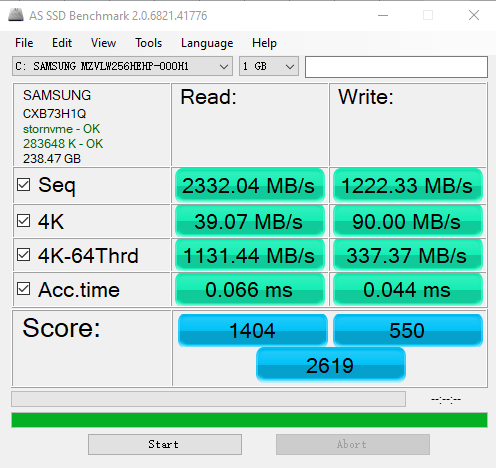
- Seq:顺序读写数据可以达到1GB-2GB/s。
- 4K:4K大小的随机读写速度只有每秒几十MB,可以算出该硬盘每秒随机读取次数可以达到1万次左右(40M/4K),随机写入可以达到每秒2万次左右。这个每秒读写的次数,我们称之为IOPS。相比较而言,HDD硬盘的IOPS通常也就在100左右(可以通过机械硬盘的转速计算出来。)。
- Acc.time
无论是顺序读写还是随机读写,SSD都远胜于HDD。但是在使用寿命上,SSD却非常差,这是受它的擦除次数限制。
对于SSD硬盘来说,数据的写入叫作Program。写入不能像机械硬盘一样,通过覆写(Overwrite)来进行的,而是要先去擦除(Erase),然后再写入。
SSD的读取和写入的基本单位,不是一个比特(bit)或者一个字节(byte),而是一个页(Page)。SSD 的擦除单位就更夸张了,我们不仅不能按照比特或者字节来擦除,连按照页来擦除都不行,我们必须按照块来擦除。对SSD来说,最好的存储介质也只有十万次的擦出次数,差一些的只有几千次。
FTL闪存转换层
为了提高SSD的使用寿命,我们要的就是想一个办法,让SSD硬盘各个块的擦除次数,均匀分摊到各个块上。这个策略呢,就叫作磨损均衡(Wear-Leveling)。实现这个技术的核心办法,和我们前面讲过的虚拟内存一样,就是添加一个间接层,就是FTL这个闪存转换层。
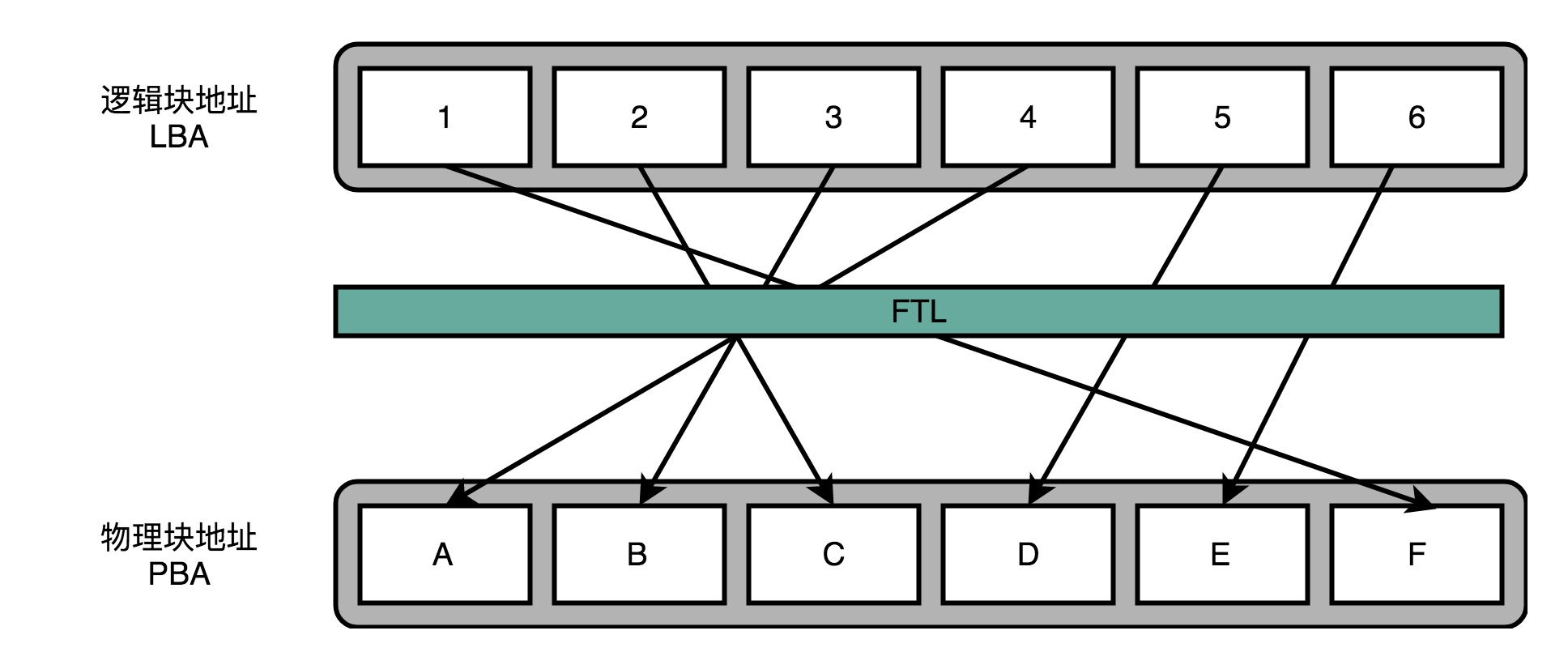
当SSD硬盘的存储空间被占用得越来越多,每一次写入新数据,我们都可能没有足够的空白。我们可能不得不去进行垃圾回收,合并一些块里面的页,然后再擦除掉一些页,才能匀出一些空间来。
这个时候,从应用层或者操作系统层面来看,我们可能只是写入了一个4KB或者4MB的数据。但是,实际通过FTL之后,我们可能要去搬运8MB、16MB甚至更多的数据。
我们通过“实际的闪存写入的数据量/系统通过FTL写入的数据量”定义写入放大。可以得到,写入放大的倍数越多,意味着实际的SSD性能也就越差,会远远比不上实际SSD硬盘标称的指标。而解决写入放大的方法:
- 需要我们在后台定时进行垃圾回收,在硬盘比较空闲的时候,就把搬运数据、擦除数据、留出空白的块的工作做完,而不是等实际数据写入的时候,再进行这样的操作。AeroSpike在某个“块”有超过50%的数据碎片时就进行垃圾回收。
- 不要存储的太满。AeroSpike数据库建议预留50%的空间。
直接内存访问(DMA)
无论I/O速度如何提升,比起CPU,总还是太慢。SSD硬盘的IOPS可以到2万、4万,但是我们CPU的主频有2GHz以上,也就意味着每秒会有20亿次的操作。
如果我们对于I/O的操作,都是由CPU发出对应的指令,然后等待I/O设备完成操作之后返回,那CPU有大量的时间其实都是在等待I/O设备完成操作。
因此,计算机工程师们,就发明了DMA技术,也就是直接内存访问(Direct Memory Access)技术,来减少CPU等待的时间。
本质上,DMA技术就是我们在主板上放一块独立的芯片。在进行内存和I/O设备的数据传输的时候,我们不再通过CPU来控制数据传输,而直接通过DMA控制器(DMA Controller,简称DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用CPU来搬运的话,肯定忙不过来,所以可以选择DMAC。而当数据传输很慢的时候,DMAC可以等数据到齐了,再发送信号,给到CPU去处理,而不是让CPU在那里忙等待。
今天,各种I/O设备越来越多,数据传输的需求越来越复杂,使用的场景各不相同。加之显示器、网卡、硬盘对于数据传输的需求都不一样,所以各个设备里面都有自己的DMAC芯片了。
为什么那么快?一起来看Kafka的实现原理
Kafka是一个用来处理实时数据的管道,我们常常用它来做一个消息队列,或者用来收集和落地海量的日志。作为一个处理实时数据和日志的管道,瓶颈自然也在I/O层面。
Kafka里面会有两种常见的海量数据传输的情况。一种是从网络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失。另一种情况呢,则是从本地磁盘上读取出来,通过网络发送出去。
Kafka做的事情就是,把这个数据搬运的次数,从上面的四次,变成了两次,并且只有DMA来进行数据搬运,而不需要CPU。
校验
- 奇偶校验和校验位
- 纠错码
- 纠删码
7-4海明码是海明吗的一种:这里的“7”指的是实际有效的数据,一共是7位(Bit)。而这里的“4”,指的是我们额外存储了4位数据,用来纠错。