极客时间-深入浅出云计算
- 01 | 区域和可用区:欢迎来到云端数据中心
- 02 | 云虚拟机(一):云端“攒机”,有哪些容易忽视的要点?
- 03 丨云虚拟机(二):眼花缭乱的虚拟机型号,我该如何选择?
- 04 丨云虚拟机(三):老板要求省省省,有哪些妙招?
- 05 | 云硬盘:云上IO到底给不给力?
- 06 | 云上虚拟网络:开合有度,编织无形之网
- 07 | 云端架构最佳实践:与故障同舞,与伸缩共生
- 08 丨云上运维:云端究竟需不需要运维?需要怎样的运维?
- 09 | 什么是PaaS?怎样深入理解和评估PaaS?
- 10 | 对象存储:看似简单的存储服务都有哪些玄机?
- 11 | 应用托管服务:Web应用怎样在云上安家?
- 12 | 云数据库:高歌猛进的数据库“新贵”
- 13 | 云上大数据:云计算遇上大数据,为什么堪称天作之合?
- 14 | 云上容器服务:从Docker到Kubernetes,迎接云原生浪潮
- 15 | 无服务器计算:追求极致效率的多面手
- 16 | 云上AI服务:云AI能从哪些方面帮助构建智能应用?
01 | 区域和可用区:欢迎来到云端数据中心
02 | 云虚拟机(一):云端“攒机”,有哪些容易忽视的要点?
传统的虚拟化(虚拟机),往往是对单一物理机器资源的纵向切割,计算、存储、网络等各方面的能力都是一台物理机的子集。因此,从可伸缩性的角度来说,传统虚拟机存在较大的局限,当物理机的局部出现故障时,也很容易影响到里面的虚拟机。
得益于云端大规模的专属硬件以及高速的内部网络,云虚拟机的组成则有所不同。除了核心的 CPU 与内存部分仍属于一台宿主机外,它的网络、硬盘等其他部分,则可以超脱于宿主机之外,享受云端其他基础设施的能力。大致架构如下图所示:
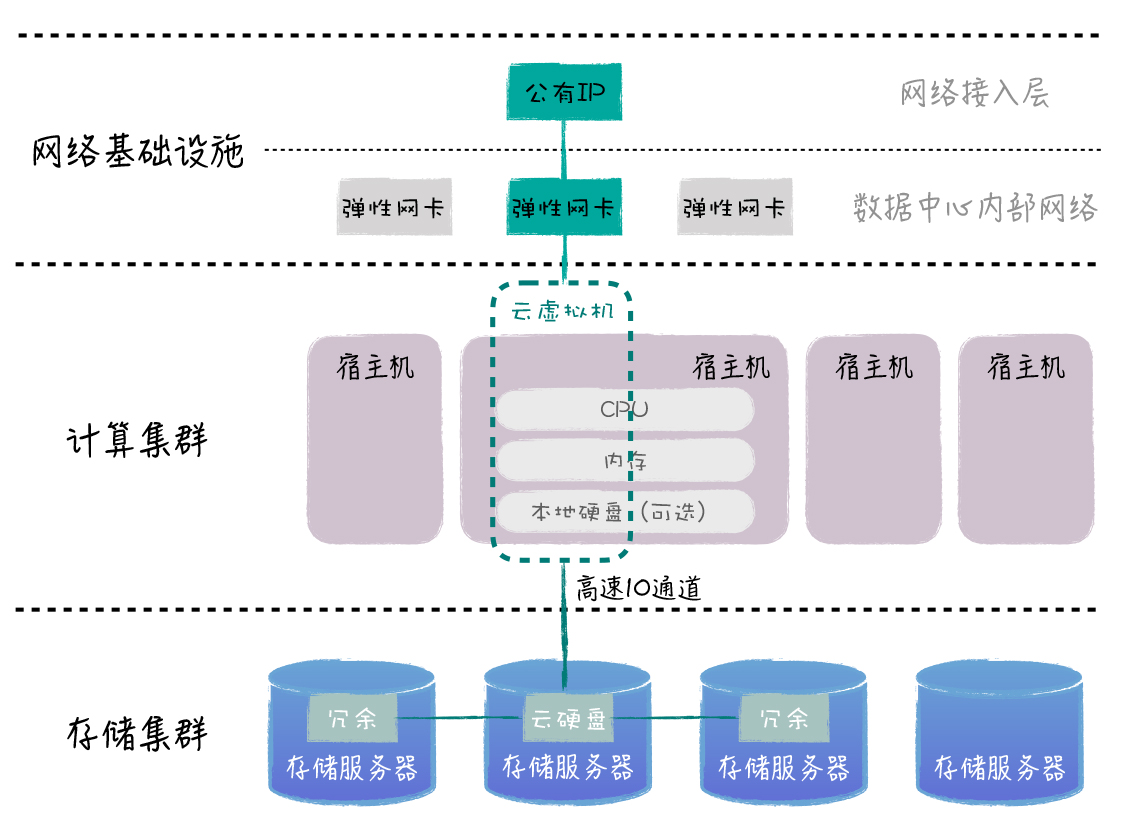
所以,云虚拟机,与其说是由一台宿主机虚拟而成的,不如说是云数据中心中的不同部分一起协作,“拼凑”而成的一台机器。这样虚拟出来的机器,我们在使用感受上其实与传统服务器并无不同,但在可扩展性和故障隔离方面,它就具有很大的优势了。
03丨云虚拟机(二):眼花缭乱的虚拟机型号,我该如何选择?
04丨云虚拟机(三):老板要求省省省,有哪些妙招?
05 | 云硬盘:云上IO到底给不给力?
云厂商对于云盘,一般会帮你在存储端同步和保留至少三份副本的数据。所以说,云硬盘的冗余度和可用性是非常之高的,一般极少发生云硬盘数据丢失的情况,你大可放心地使用。
云盘性能指标:
- IOPS
- 吞吐量
- 访问延时
云硬盘与传统磁盘的真正差异在于,绝大多数的云硬盘都是远程的。
我们都知道,在经典计算机的体系结构中,硬盘是通过本地机器内部主板的高速总线,与 CPU、内存等部件相连接;而在云端,你的硬盘则很可能并不在宿主机上,而是在专用的磁盘服务器阵列中,两者是通过数据中心内部的特有IO线路进行连接的。
理解了这样的一个结构,你就能明白,有些云上的“IO优化实例”(AWS 上称为 EBS-Optimized)是指什么了。它就是指云虚拟机与云硬盘之间的网络传输,进行了软硬件层面的优化,这样可以充分地发挥所挂载磁盘的性能。现在较新型号、较强性能的云虚拟机,一般都自动启用了这个优化。
云存储的性能级别:
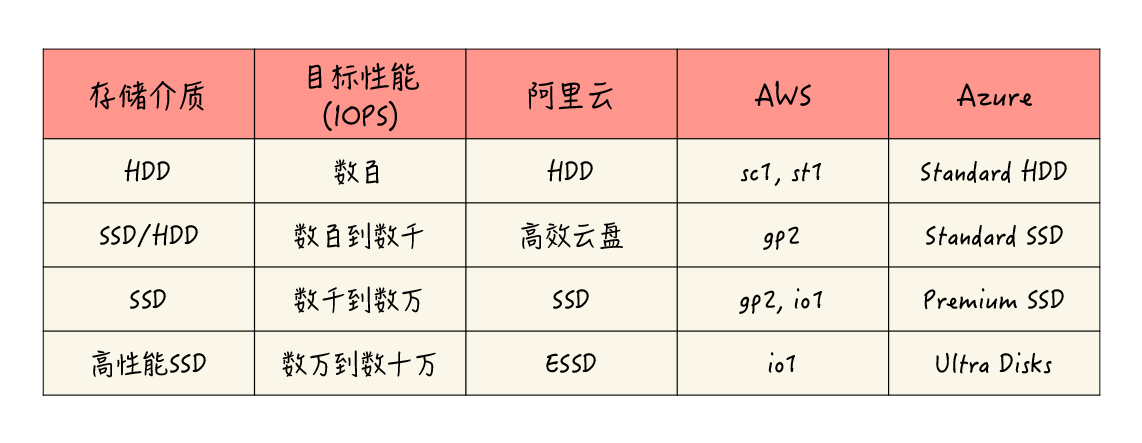
除了云盘性能等级,还有一个指标也是影响云盘性能的重要指标:云盘容量。不论是哪种磁盘类型,它的容量大小几乎都与性能正向相关。同等的性能等级下,云硬盘的容量越大,一般来说它的性能就越高,直到达到这个等级的上限。这是由云上磁盘能力共享的底层设计所决定的。
所以在某些时候,你可能需要刻意地增大所申请的云硬盘的容量,以获取更高的性能,即便这些额外的空间不一定能被用上。
06 | 云上虚拟网络:开合有度,编织无形之网
虚拟私有网络(Virtual Private Cloud,简称 VPC),是云计算网络端最重要的概念之一,它是指构建在云上的、相互隔离的、用户可以自主控制的私有网络环境。虚拟私有网络有时也称为专有网络(阿里云)或虚拟网络(Virtual Network 或 VNet,Azure 的叫法)。
上面的概念解释也许不太好理解,其实用通俗的话来讲,私有网络就是一张属于你自己的内网。内网之内的服务器和设备,可以比较自由地互相通信,与外界默认是隔离的。如果外部互联网,或者其他虚拟网络需要连接,则需要额外的配置。
所以说,虚拟私有网络,就是你在云上的保护网,能够有效地保护网内的各种设施。有的时候,你可能还要同时创建多个虚拟网络,让它们各司其职,实现更精细的隔离。
弹性网卡
云上的网卡,之所以被称为“弹性”网卡,是因为它具备以下特征:
- 一个虚拟机可以绑定多块网卡,有主网卡和辅助网卡之分;
- 一块网卡隶属于一个子网,可以配置同一子网内的多个私有 IP;
- 辅助网卡可以动态解绑,还能够绑定到另一台虚拟机上。
公网IP和弹性IP
在绝大多数的云上,创建虚拟机时都会有一个选项,问你“是否同时为虚拟机分配一个公网 IP 地址”。如果你选择“是”,这样机器启动后,就会拥有一个自动分配的公网地址,便于你从自己的电脑连接到这个实例。这在很多时候都是最方便的选择。
但对于生产环境,我的推荐是,尽量不要使用和依赖这个自动生成的公有 IP。因为它本质上是一个从公有云的 IP 池中临时租用给你的 IP。如果你的机器关闭或重启,下次获得的 IP 可能就完全不同了。
这时,我们真正应该用到的是弹性 IP(Elastic IP),有些云称为 eIP。弹性 IP 一旦生成,它所对应的 IP 是固定、不会变化的,而且完全属于你所有。这非常适合需要稳定 IP 的生产环境。
请不要被它的名字迷惑,它所谓的弹性,其实是指可以非常自由地解绑和再次绑定到任意目标。你本质上是买下了这个 IP 的所有权,将这个 IP 赋予谁,是你的权利,而且你还可以动态按需切换。
07 | 云端架构最佳实践:与故障同舞,与伸缩共生
云上架构最需要注意什么呢?就像我在标题所描述的那样,云端架构一方面需要处理和应对可能出现的故障,保证架构和服务的可用性;另一方面则是需要充分利用好云端的弹性,要能够根据负载进行灵活的伸缩。
那么,云上可能出现哪些不同层面的故障?相应的故障范围和应对措施又会是怎样的呢?
第一种故障是在宿主机的级别,这也是从概率上来说最常见的一种故障。当宿主机出现硬件故障等问题后,毫无疑问将影响位于同一宿主机上的多个虚拟机。为了避免产生这样的影响,当我们承载重要业务时,就需要创建多台虚拟机组成的集群,共同来进行支撑。这样,当一台虚拟机出现故障时,还有其他几台机器能够保证在线。
这里需要注意的是,我们需要保证多个虚拟机不在同一台宿主机上,甚至不处于同一个机架上,以免这些虚拟机一起受到局部事故的影响。
第二种规模更大的故障,是在数据中心,也就是可用区的层面。要应对这类故障,我们就需要多可用区的实例部署。
第三种更严重的故障,就是整个区域级别的事故了。当然这种一般非常少见,只有地震等不可抗力因素,或者人为过失引发出的一系列连锁反应,才有可能造成这么大的影响。区域级别的事故一般都难免会对业务造成影响了。这时能够进行补救的,主要看多区域架构层面是否有相关的预案。
再更进一步的万全之策,就需要考虑多云了。也就是同时选用多家云厂商的公有云,一起来服务业务。虽然集成多个异构的云会带来额外的成本,但这能够最大限度地降低服务风险,因为两家云厂商同时出问题的概率实在是太低了。更何况,多云还能带来避免厂商锁定的好处,现在其实也越来越多见了。
当然,盲目地追求可用性也不可取。根据业务需求,在成本投入与可用性之间获得一个最佳的平衡,才是你应该追求的目标。
08丨云上运维:云端究竟需不需要运维?需要怎样的运维?
09 | 什么是PaaS?怎样深入理解和评估PaaS?
PaaS 是在 IaaS 的基础上又做了许多工作,构建了很多关键抽象和可复用的单元,让我们用户能够在更上层进行应用的构建,把更多精力放在业务逻辑上。
所以 PaaS 服务的优势,就在于生产力,在于效率,尤其是在搭建和运维层面。
10 | 对象存储:看似简单的存储服务都有哪些玄机?
同样是存储服务,对象存储和前面我们 IaaS 部分讲过的云硬盘存储有什么区别呢?
第一个主要区别,在于访问的接口与形式。
云硬盘其实是挂载到虚拟机的虚拟硬盘,它是通过实现操作系统级别的底层接口,作为虚拟机的块存储设备而存在。我们也必须连接到相关的虚拟机,才能访问它里面的数据。
而对象存储,本质是一个网络化的服务,调用方主要通过高层的 API 和 SDK 来和它进行交互。不管是面向外部公开互联网服务,还是和内部应用程序对接,对象存储都是通过提供像 HTTP 这样的网络接口来实现的。所以它的独立性很强,不需要依赖其他组件就可以运作。
第二个主要区别,也是对象存储的一大特征,就是对象存储内本身不存在一个真正的文件系统,而是更接近一个键值(Key-Value)形式的存储服务。
键值系统和云硬盘上经典文件系统的核心差异,就在于文件系统保存了更多的元数据,尤其是实现了目录结构和目录操作。而键值系统中,所谓的目录其实是多个对象共享的路径前缀,可以说是用前缀模拟出了目录。
第三个主要区别,在于对象存储的据大容量。
对象存储的高级特性
第一个重要特性,是存储分层。
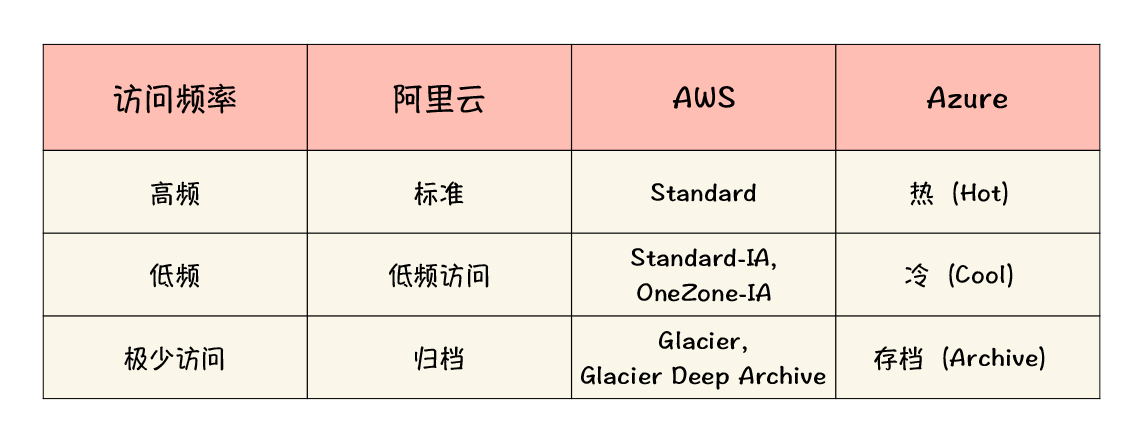
存储分层的存在,让原本价格低廉的云上存储更加具有成本竞争力。给你举个例子,现在归档层的存储费用,在典型情况下大约是每 GB 每月 1 分钱左右,是不是低得惊人?所以,很多用户上云的一个应用场景就是,把原本占用大量传统磁盘的备份文件,利用对象存储的归档能力长期保存。
第二个值得称道的特性,是生命周期管理。可以对存储对象设置过期规则。
第三个特性,则是对象的版本管理。
11 | 应用托管服务:Web应用怎样在云上安家?
你可以使用虚拟机和其他 IaaS 组件来搭建你的网站。但用 IaaS,你需要操心的事情比较多,包括虚拟机的创建、运行环境的搭建和依赖安装、高可用性和水平扩展的架构等等。而且一旦应用的规模大了,每次应用的更新升级也会是件麻烦事,另外你还要操心 Web 漏洞的弥补修复。
那么,能不能有一个平台服务,来帮助我们解决所有这些基础架构问题,让我们只需要专注于应用构建本身就好了呢?当然是有的,这就是云上应用托管 PaaS 服务的由来。
12 | 云数据库:高歌猛进的数据库“新贵”
而近年来随着云计算的兴起,云数据库作为一支新生力量,一路高歌猛进,打破了数据库市场的原有格局,也进入了越来越多开发者的视野当中。这类 PaaS 服务的朴素思想就是,将数据库服务搬到云上,让用户更方便轻松地使用、管理和维护数据库。
云原生数据库
云原生数据库:完全为云设计、能够充分发挥云的特点和优势的数据库。
出于生态发展和降低学习难度的需要,绝大多数的云原生数据库仍然保留了 SQL 等常见接口(有的还支持不同 SQL 方言的选择),但除此以外,云原生数据库大都进行了全面革新和重新设计,有的云会大刀阔斧地改造开源代码,有的甚至脱离了现有包袱,完全重新构建。
这样的尝试取得了巨大的成功,业界也逐渐形成了一系列不同领域的云原生数据库矩阵,大大拓展了云上数据库的范畴和影响力。
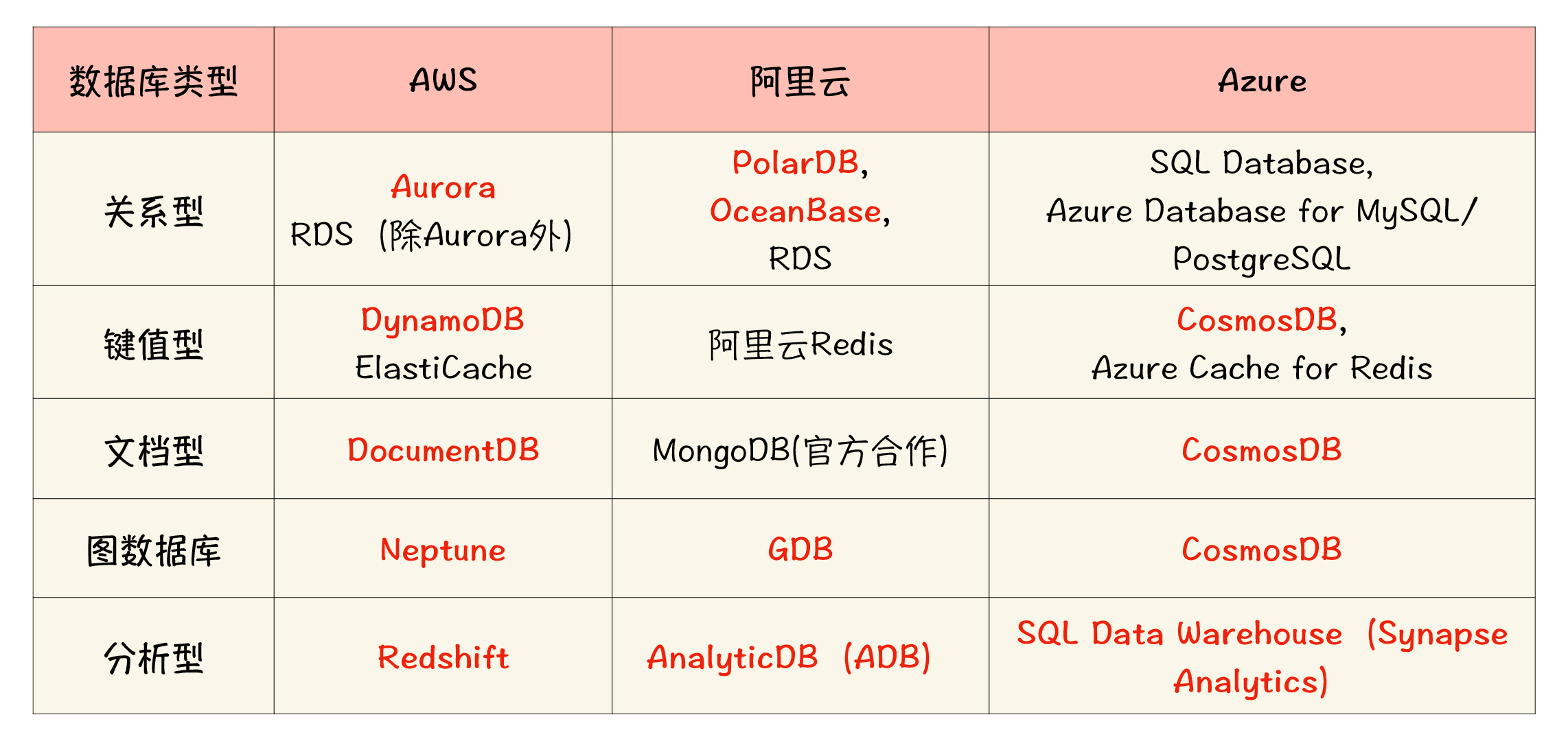
我这里也为你整理了一张表格,按照厂商和云数据库的类型进行了梳理和比较。其中,标红的部分是相当值得你关注的自研云原生数据库。
13 | 云上大数据:云计算遇上大数据,为什么堪称天作之合?
14 | 云上容器服务:从Docker到Kubernetes,迎接云原生浪潮
15 | 无服务器计算:追求极致效率的多面手
无服务器(Serverless)完全屏蔽了计算资源,它是在真正地引导你不再去关心底层环境,你只要遵循标准方式来直接编写业务代码就可以了。其中一个具体应用就是函数即服务(FaaS,Function as a service)。
各大云厂商现在都已经推出了各自的无服务器计算服务,比如 AWS 的 Lambda,阿里云的函数计算,微软Azure的Azure Function,微信的云函数。
为了让这个云函数能够对外服务,我们接下来就需要为它添加一个 API网关触发器,这样当 API 被外界访问时,这个云函数就会被触发执行并返回结果给网关。
API 网关是一个独立的 PaaS 服务,它可以和云函数联动使用。它的作用是为外界访问提供一个端点,并引流到我们的后台计算服务。
无服务器计算灵活轻量,便于迭代。但是,我们还是要记得恪守冷静客观的原则。一定不要忽略了 Serverless 服务的限制,毕竟它的本质是受限的环境。冷启动的延时、内存的限制、云函数的运行时长、并发数上限等等,这些都是你大规模深入应用之前需要评估考虑的问题。虽然云厂商一直在改进,这些客观限制在当下对于你的场景是否造成了实质性障碍,也是你目前是否选择 Serverless 计算的一个重要依据。